模型代码解读#
模型结构图#
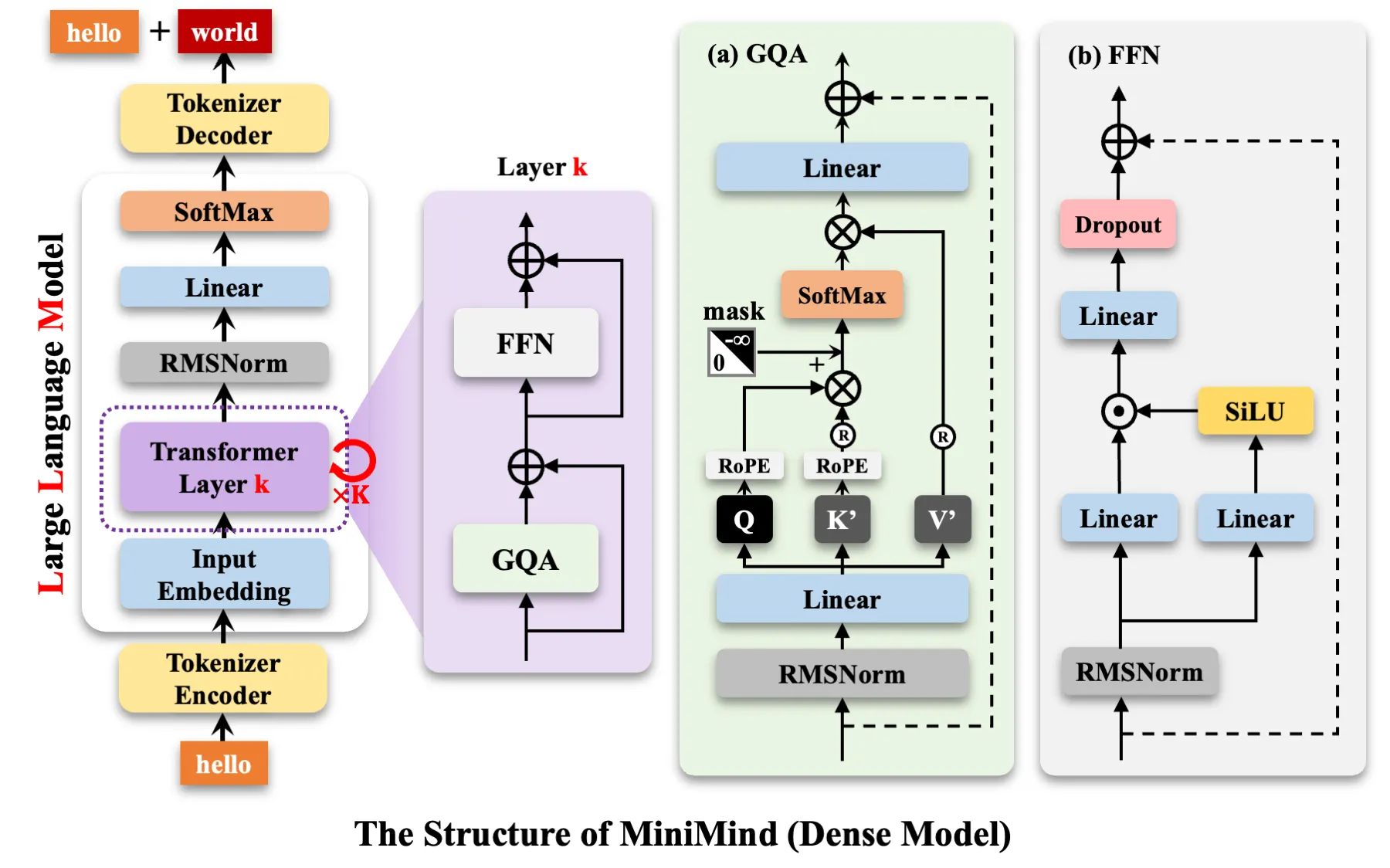
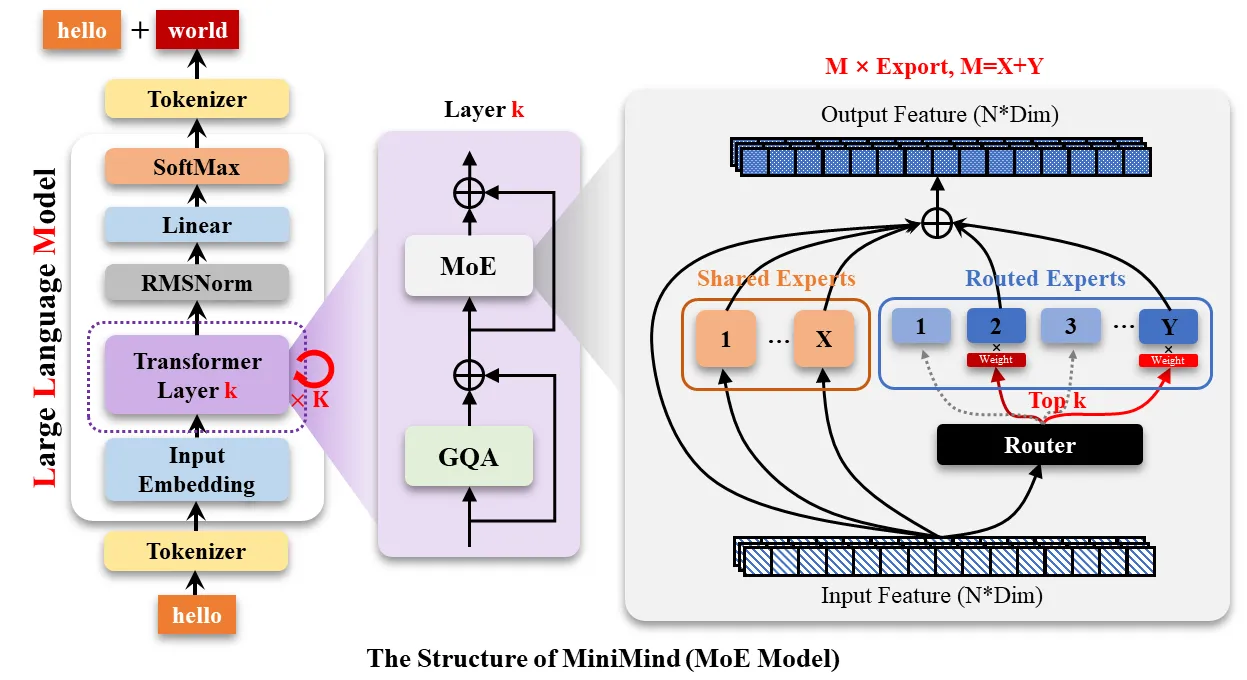
Dense模型和Moe模型:
模型配置#
from transformers import PretrainedConfig
class MiniMindConfig(PretrainedConfig):
model_type = "minimind"
def __init__(
self,
dropout: float = 0.0,
bos_token_id: int = 1,
eos_token_id: int = 2,
hidden_act: str = 'silu',
hidden_size: int = 512,
intermediate_size: int = None,
max_position_embeddings: int = 32768,
num_attention_heads: int = 8,
num_hidden_layers: int = 8,
num_key_value_heads: int = 2,
vocab_size: int = 6400,
rms_norm_eps: float = 1e-05,
rope_theta: int = 1000000.0,
inference_rope_scaling: bool = False,
flash_attn: bool = True,
####################################################
# Here are the specific configurations of MOE
# When use_moe is false, the following is invalid
####################################################
use_moe: bool = False,
num_experts_per_tok: int = 2,
n_routed_experts: int = 4,
n_shared_experts: int = 1,
scoring_func: str = 'softmax',
aux_loss_alpha: float = 0.1,
seq_aux: bool = True,
norm_topk_prob: bool = True,
**kwargs
):
super().__init__(**kwargs)
self.dropout = dropout
self.bos_token_id = bos_token_id
self.eos_token_id = eos_token_id
self.hidden_act = hidden_act
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.max_position_embeddings = max_position_embeddings
self.num_attention_heads = num_attention_heads
self.num_hidden_layers = num_hidden_layers
self.num_key_value_heads = num_key_value_heads
self.vocab_size = vocab_size
self.rms_norm_eps = rms_norm_eps
self.rope_theta = rope_theta
self.inference_rope_scaling = inference_rope_scaling
# 外推长度 = factor * original_max_position_embeddings
self.rope_scaling = {
"beta_fast": 4,
"beta_slow": 1,
"factor": 4,
"original_max_position_embeddings": 2048,
"type": "yarn"
} if self.inference_rope_scaling else None
self.flash_attn = flash_attn
####################################################
# Here are the specific configurations of MOE
# When use_moe is false, the following is invalid
####################################################
self.use_moe = use_moe
self.num_experts_per_tok = num_experts_per_tok # 每个token选择的专家数量
self.n_routed_experts = n_routed_experts # 总的专家数量
self.n_shared_experts = n_shared_experts # 共享专家
self.scoring_func = scoring_func # 评分函数,默认为'softmax'
self.aux_loss_alpha = aux_loss_alpha # 辅助损失的alpha参数
self.seq_aux = seq_aux # 是否在序列级别上计算辅助损失
self.norm_topk_prob = norm_topk_prob # 是否标准化top-k概率PretrainedConfig是MiniMindConfig的基类,定义了模型架构所需的重要参数,包括:
- hidden_size: 模型隐藏层的大小。
- num_hidden_layers: Transformer模型的层数。
- num_attention_heads: 多头注意力机制中注意力头的数量。
- vocab_size: 词汇表的大小。
- 以及其他特定于模型的超参数,例如激活函数、dropout比例等。
核心参数#
这些参数决定了模型的身材和体型,核心为d_model(hidden_size)和n_layers(num_hidden_layers)
- hidden_size: int = 512:这是最重要的参数之一,决定了模型用来表示每个“词”的向量(一串数字)的维度,可以把它理解为模型对一个词的理解深度。hidden_size越大,模型能捕捉到的词语的细节就越丰富,但模型的体积也会更大,计算会更慢。
- num_hidden_layers: int = 8:Transformer模型是由一层层相同的结构堆叠而成的。这个参数就是设置要堆叠多少层。层数越多,模型处理信息和学习复杂规律的步骤就越多,理解能力也可能越强。
- num_attention_heads: int = 8:“注意力机制”是Transformer的核心,它能让模型在处理一个词时,判断句子中其他词对它的重要性。目前普遍采用多头注意力机制,让模型可以同时从不同角度关注句子的不同方面。
- num_key_value_heads: int = 2:这是一个更高级的优化技术(分组查询注意力)。简单来说,它允许模型在注意力计算中共享一部分信息,从而在不严重影响性能的情况下提升计算速度。
- intermediate_size: int = None:在每一层网络中,都有一个“前馈网络”用来进一步处理信息。这个参数控制了该网络中间层的大小。如果设为None,代码会自动计算一个合适的尺寸。
- vocab_size: int = 6400:这代表模型的“词汇表”大小。也就是模型认识和能够生成的所有独立的token总数量。
README中提到:
d_model↑ +n_layers↓ -> 矮胖子d_model↓ +n_layers↑ -> 瘦高个2020年提出Scaling Law的论文认为,训练数据量、参数量以及训练迭代次数才是决定性能的关键因素,而模型架构的影响几乎可以忽视。 然而似乎这个定律对小模型并不完全适用。 MobileLLM提出架构的深度比宽度更重要,「深而窄」的「瘦长」模型可以学习到比「宽而浅」模型更多的抽象概念。 例如当模型参数固定在125M或者350M时,30~42层的「狭长」模型明显比12层左右的「矮胖」模型有更优越的性能, 在常识推理、问答、阅读理解等8个基准测试上都有类似的趋势。 这其实是非常有趣的发现,因为以往为100M左右量级的小模型设计架构时,几乎没人尝试过叠加超过12层。 这与MiniMind在训练过程中,模型参数量在
d_model和n_layers之间进行调整实验观察到的效果是一致的。 然而「深而窄」的「窄」也是有维度极限的,当d_model<512时,词嵌入维度坍塌的劣势非常明显, 增加的layers并不能弥补词嵌入在固定q_head带来d_head不足的劣势。 当d_model>1536时,layers的增加似乎比d_model的优先级更高,更能带来具有”性价比”的参数->效果增益。
- 因此MiniMind设定small模型dim=512,n_layers=8来获取的「极小体积<->更好效果」的平衡。
- 设定dim=768,n_layers=16来获取效果的更大收益,更加符合小模型Scaling-Law的变化曲线。
微调模型性能参数#
这些参数用于微调模型的性能和行为。
- dropout: float = 0.0:一种防止模型过度“死记硬背”训练数据(即“过拟合”)的技术。在训练时,它会随机地让一些神经元“失活”,从而让模型学习得更扎实、更通用。0.0表示不使用这个技术。
- hidden_act: str = ‘silu’:指定“激活函数”,这是一种数学函数,能帮助模型学习非线性的复杂模式。silu是目前一种非常流行且效果很好的选择。
- rms_norm_eps: float = 1e-05:这是一个用在RMSNorm中的极小值,目的是防止计算中出现除以零的错误。RMSNorm是一种归一化技术,能让模型的训练过程更稳定、更高效。
- flash_attn: bool = True:启用“Flash Attention”。这是一种高度优化的注意力机制算法,尤其在处理长句子时,它的计算速度更快,占用内存也更少。
理解词语顺序:位置编码#
Transformer模型天生不理解词语的顺序。以下参数帮助模型理解每个词在句子中的位置。
- max_position_embeddings: int = 32768:设定模型能处理的句子的最大长度(以token计)。
- rope_theta: int = 1000000.0:这是旋转位置编码 (RoPE) 的一个参数。RoPE是一种非常巧妙的位置编码技术,它不是简单地给每个位置一个编号,而是根据词语的位置来“旋转”它的词向量。这使得模型能更好地理解词语之间的相对位置关系。
- inference_rope_scaling: bool = False:一个高级开关。如果开启,可以通过特定算法让训练好的模型能够处理比原先设定更长的句子。
混合专家模型 (Mixture of Experts, MoE)#
这是MiniMind模型一个非常强大的特性。想象一下,你有一个非常复杂的问题,与其让一个“通才”专家来解决,不如请一个由多位“专才”组成的团队来解决。这就是MoE的核心思想。
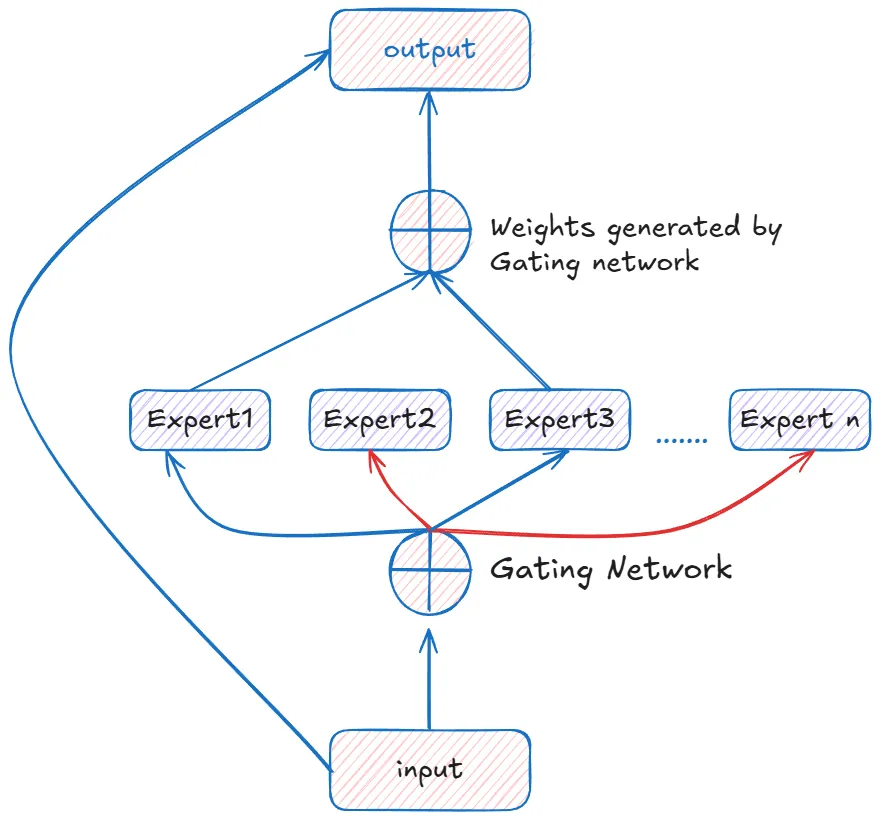
- use_moe: bool = False:这是开启或关闭MoE功能的总开关。
- n_routed_experts: int = 4:设定在MoE层中,总共有多少个“专家”(独立的神经网络模块)可供选择。
- num_experts_per_tok: int = 2:对于句子中的每一个词(token),模型会从所有专家中挑选出最合适的 2 个来处理它。
- n_shared_experts: int = 1:除了那些被挑选的“专才”专家,还可以设置1个或多个“共享”专家,它们会处理每一个输入的词。这有助于模型保持一些通用知识。
- 其他MoE参数 (scoring_func, aux_loss_alpha等) 都是一些更技术性的设置,用于控制“门控网络”(负责挑选专家的模块)如何训练以及如何工作。
MoE最大的好处是:你可以拥有一个参数量巨大(因此知识渊博)的模型,但在处理任何一个词时,你只需要激活其中一小部分的参数。这使得模型在训练和推理(使用)时,比同样参数规模的传统模型要快得多。
模型本体(MinMindModel类)#
1. RMSNorm#
# RMSNorm 类,继承自 nn.Module 以获得所有基础功能
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
# 初始化父类
super().__init__()
# eps 是一个很小的数,防止计算中除以零
self.eps = eps
# 定义一个可学习的缩放参数 weight,并初始化为全1
# nn.Parameter 会将这个张量注册为模型的参数,使其可以被优化器更新
self.weight = nn.Parameter(torch.ones(dim))
# 这是一个内部辅助函数,实现了 RMSNorm 的核心数学计算
def _norm(self, x):
# 1. x.pow(2): 计算输入 x 中每个元素的平方
# 2. .mean(-1, keepdim=True): 沿着最后一个维度(特征维度)计算平方的均值
# keepdim=True 保持了维度,例如 (batch, seq_len, dim) -> (batch, seq_len, 1)
# 3. + self.eps: 加上极小值 eps
# 4. torch.rsqrt(...): 计算结果的平方根的倒数,即 1/sqrt(...),这比直接除法效率更高
# 5. x * ...: 将原始输入 x 乘以这个倒数,完成归一化
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
# forward 方法定义了数据如何流过这个模块
def forward(self, x):
# 1. self._norm(x.float()): 调用核心计算函数对输入 x 进行归一化。
# x.float() 是为了保证计算精度
# 2. .type_as(x): 将计算结果的数据类型转换回原始输入 x 的类型 (例如 float16)
# 3. self.weight * ...: 将归一化后的结果乘以可学习的缩放参数 weight
return self.weight * self._norm(x.float()).type_as(x)
RMSNorm是一个用于稳定训练的归一化层。
- 初始化
__init__:- 它接收
dim(输入向量的维度)和eps作为参数。 - 核心是
self.weight = nn.Parameter(torch.ones(dim))这一行。nn.Parameter是一个特殊的张量,它告诉PyTorch:“这是一个模型参数,你需要在训练时计算它的梯度并用优化器更新它”。weight的作用是在归一化之后,让网络可以学习如何对特征进行重新缩放,保留模型的表达能力。
- 它接收
- 核心计算
_norm:- 这一小段代码完美实现了RMSNorm的数学公式。关键点在于
.mean(-1, keepdim=True),它沿着每个词元(token)的特征维度(dim)计算均值,并且保持维度不变,这样结果张量才能和原始输入x进行广播(element-wise)乘法。 - 使用
torch.rsqrt(平方根倒数) 是一个常见的性能优化技巧。
- 这一小段代码完美实现了RMSNorm的数学公式。关键点在于
- 前向传播
forward:- 这是模块被调用时执行的函数。它将输入
x通过_norm函数进行归一化,然后乘以可学习的self.weight。 .type_as(x)确保了即使在内部为了精度使用了float计算,最终输出的数据类型也与输入保持一致,这对于混合精度训练很重要。
- 这是模块被调用时执行的函数。它将输入
2. precompute_freqs_cis 和 apply_rotary_pos_emb (RoPE)#
# 函数:预计算旋转位置编码所需的 cos 和 sin 值
def precompute_freqs_cis(dim: int, end: int = int(32 * 1024), rope_base: float = 1e6,
rope_scaling: Optional[dict] = None):
# 1. 计算基础频率 freqs。这是RoPE的核心,不同的维度会有不同的旋转速度。
freqs = 1.0 / (rope_base ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# (这部分是高级功能,用于处理超长文本,可以暂时忽略)
if rope_scaling is not None:
# ... YaRN scaling logic ...
pass
# 2. 生成所有可能的位置序列 t,从 0 到 end-1
t = torch.arange(end, device=freqs.device)
# 3. 计算每个位置 t 和每个频率 freqs 的相位角
# torch.outer(t, freqs) 的结果是一个 (end, dim/2) 的矩阵,代表了每个位置在每个频率上的角度
freqs = torch.outer(t, freqs).float()
# 4. 计算所有角度的 cos 值和 sin 值,并拼接起来,形成最终的预计算表
# freqs_cos 和 freqs_sin 的维度都是 (end, dim)
freqs_cos = torch.cat([torch.cos(freqs), torch.cos(freqs)], dim=-1)
freqs_sin = torch.cat([torch.sin(freqs), torch.sin(freqs)], dim=-1)
return freqs_cos, freqs_sin
# 函数:将RoPE应用到 Query 和 Key 向量上
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
# 内部函数:将向量的后半部分和前半部分对调,并给后半部分取反,模拟复数中的乘以 i
def rotate_half(x):
return torch.cat((-x[..., x.shape[-1] // 2:], x[..., : x.shape[-1] // 2]), dim=-1)
# RoPE的核心公式:q_rot = q * cos + rotate_half(q) * sin
# 这在数学上等价于用一个旋转矩阵去乘以 q 向量
q_embed = (q * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(q) * sin.unsqueeze(unsqueeze_dim))
k_embed = (k * cos.unsqueeze(unsqueeze_dim)) + (rotate_half(k) * sin.unsqueeze(unsqueeze_dim))
return q_embed, k_embed
这两个函数共同实现了旋转位置编码(RoPE)。
precompute_freqs_cis:- 目的:一次性计算好所有位置可能用到的
cos和sin值,避免在每次前向传播时重复计算,提升效率。 - 流程:它首先根据
rope_base和维度dim计算出一组基础的旋转“角速度”(freqs)。然后,它为每一个绝对位置(从0到end)和每一个角速度计算出具体的旋转角度,并求出这些角度的cos和sin值。最终返回两个巨大的查找表freqs_cos和freqs_sin。
- 目的:一次性计算好所有位置可能用到的
apply_rotary_pos_emb:- 目的:在模型运行时,将位置信息“注入”到Query和Key向量中。
- 流程:它接收Q和K向量,以及从预计算表中取出的对应当前序列长度的
cos和sin片段。 rotate_half函数是实现旋转的关键。RoPE将每个向量看作是一系列二维坐标点,rotate_half的操作配合cos和sin的乘法,就完成了对这些二维坐标点的旋转。- 最终,
q_embed和k_embed就是携带了位置信息的新Q和K向量。
3. Attention#
class Attention(nn.Module):
def __init__(self, args: MiniMindConfig):
super().__init__()
# ... 初始化参数 ...
self.n_local_heads = args.num_attention_heads
self.n_local_kv_heads = args.num_key_value_heads
self.n_rep = self.n_local_heads // self.n_local_kv_heads # 每个KV头被共享的次数
self.head_dim = args.hidden_size // args.num_attention_heads
# 定义Q, K, V的线性投影层
self.q_proj = nn.Linear(args.hidden_size, args.num_attention_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(args.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(args.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
# 定义输出的线性投影层
self.o_proj = nn.Linear(args.num_attention_heads * self.head_dim, args.hidden_size, bias=False)
# ... dropout 和 flash attention 开关 ...
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and args.flash_attn
def forward(self, x, position_embeddings, past_key_value=None, use_cache=False, attention_mask=None):
bsz, seq_len, _ = x.shape
# 1. 将输入 x 通过线性层计算出 Q, K, V
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)
# 2. 将Q,K,V的形状调整为 (batch_size, seq_len, num_heads, head_dim) 以便多头并行计算
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
# 3. 应用旋转位置编码 (RoPE)
cos, sin = position_embeddings
xq, xk = apply_rotary_pos_emb(xq, xk, cos[:seq_len], sin[:seq_len])
# 4. KV 缓存机制 (用于加速推理)
if past_key_value is not None:
# 将过去的 K, V 和当前的 K, V 拼接起来
xk = torch.cat([past_key_value[0], xk], dim=1)
xv = torch.cat([past_key_value[1], xv], dim=1)
past_kv = (xk, xv) if use_cache else None
# 5. 为了计算,将维度调整为 (bsz, num_heads, seq_len, head_dim)
# 并使用 repeat_kv 实现分组查询注意力 (GQA),让多个Q头共享K,V头
xq, xk, xv = (
xq.transpose(1, 2),
repeat_kv(xk, self.n_rep).transpose(1, 2),
repeat_kv(xv, self.n_rep).transpose(1, 2)
)
# 6. 计算注意力分数并得到输出
if self.flash: # 如果支持并开启了Flash Attention
# 使用PyTorch内置的高度优化的注意力实现,速度快,省内存
output = F.scaled_dot_product_attention(xq, xk, xv, is_causal=True)
else: # 使用手动实现的注意力
# Q 和 K 的转置相乘,得到注意力分数
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 添加因果掩码,防止看到未来的信息
scores = scores + torch.triu(...)
# ... (处理额外的 attention_mask) ...
# Softmax 将分数转换为概率
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
# 概率与 V 相乘,得到加权和
output = scores @ xv
# 7. 整理输出形状并通过输出投影层
output = output.transpose(1, 2).reshape(bsz, seq_len, -1)
output = self.o_proj(output)
return output, past_kv
Attention是模型的核心。
- Q,K,V生成 (步骤1-2): 输入
x(维度为hidden_size)通过三个独立的线性层q_proj,k_proj,v_proj,被“投影”成Q, K, V。然后.view()方法将它们的形状调整为多头格式,准备并行计算。 - 位置编码 (步骤3): 调用
apply_rotary_pos_emb函数,将位置信息注入到刚生成的Q和K中。 - KV缓存 (步骤4): 这是文本生成时的一个关键优化。在生成第N个词时,我们不需要重新计算前N-1个词的K和V,只需将它们缓存下来,与当前第N个词的K,V拼接即可。
use_cache=True时会启用此功能。 - 注意力计算 (步骤5-6):
repeat_kv实现了分组查询注意力(GQA)。例如,如果有8个Q头和2个KV头,n_rep就是4,它会将2个KV头分别复制4次,来匹配8个Q头。这比传统的MHA(Multi-Head Attention)更节省内存。- 代码在这里有一个分支:如果环境支持且配置开启了
flash_attn,它会调用F.scaled_dot_product_attention。这是一个融合了计算、掩码、Softmax等步骤的高度优化的内核,是当前Transformer加速的主流方案。否则,它会一步步地手动实现注意力计算。
- 输出 (步骤7): 计算完成的
output需要被重新整形,并通过o_proj线性层进行最后的信息整合,将维度变回hidden_size,以便输入到下一层。
4 & 5. FeedForward, MoEGate 和 MOEFeedForward#
class FeedForward(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
# ... 自动计算中间层大小 ...
# SwiGLU结构包含三个线性层
self.gate_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.down_proj = nn.Linear(config.intermediate_size, config.hidden_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, config.intermediate_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act] # 激活函数,例如 SiLU
def forward(self, x):
# SwiGLU的计算公式: (x @ W_gate * act_fn(x @ W_up)) @ W_down
# 这里 act_fn(self.gate_proj(x)) 和 self.up_proj(x) 的顺序与公式略有不同,但本质相同
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
这是一个标准的FFN层,但使用了高效的SwiGLU结构。它的作用是在注意力层聚合了信息之后,对每个词元的信息进行一次非线性的、深度的加工。你可以把它看作是模型“思考”和“消化”信息的地方。
class MOEFeedForward(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
# 1. 创建多个独立的 FeedForward 网络作为“专家”
self.experts = nn.ModuleList([FeedForward(config) for _ in range(config.n_routed_experts)])
# 2. 创建一个门控网络,用于决定使用哪些专家
self.gate = MoEGate(config)
# ... (共享专家逻辑) ...
def forward(self, x):
# ...
# 3. 使用门控网络为每个词元选择 top-k 个专家,并计算权重
topk_idx, topk_weight, aux_loss = self.gate(x)
# ...
# 4. 将输入 x 发送给被选中的专家进行处理
# (训练和推理时的实现细节不同,但目标一致)
# 例如训练时:
y = torch.empty_like(x_repeated)
for i, expert in enumerate(self.experts):
# 找到所有应该由第 i 个专家处理的 token
# expert(...) 对这些 token 进行 FFN 计算
y[flat_topk_idx == i] = expert(x[flat_topk_idx == i])
# 5. 将多个专家的输出根据门控权重进行加权求和
y = (y.view(...) * topk_weight.unsqueeze(-1)).sum(dim=1)
# ...
return y
如果配置中启用了MoE,MOEFeedForward会取代FeedForward。
- 构造: 它初始化了多个独立的
FeedForward实例,称为“专家”(self.experts),以及一个MoEGate。 - 门控: 在
forward方法中,它首先将输入x传递给self.gate。MoEGate的核心是一个线性层,它会输出一个分数,代表每个专家处理当前词元的“合适程度”。然后通过topk选出分数最高的几个专家(数量由num_experts_per_tok决定)。 - 路由与计算: 接着,模型会根据
gate的选择,将输入x“路由”给对应的专家。代码中为了效率,会进行一些重排操作,将发往同一个专家的所有词元打包在一起,进行一次批处理。 - 融合: 每个被选中的专家都会输出一个结果,最后将这些结果根据
gate给出的权重(topk_weight)进行加权求和,得到最终的输出。
一句话总结MoE:它用一个轻量级的“门控”网络,来决定为每个词元激活哪几个重量级的“专家”网络,从而在保持单次计算量可控的同时,极大地扩展了模型的总知识容量。
6. MiniMindBlock#
class MiniMindBlock(nn.Module):
def __init__(self, layer_id: int, config: MiniMindConfig):
super().__init__()
# 初始化一个 Attention 模块
self.self_attn = Attention(config)
# 初始化输入和后注意力层的归一化模块
self.input_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 根据配置,选择使用普通的 FFN 还是 MoE 模块
self.mlp = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
def forward(self, hidden_states, position_embeddings, past_key_value=None, use_cache=False, attention_mask=None):
# 1. 第一个残差连接 (Residual Connection)
residual = hidden_states
# 2. Pre-Norm: 先归一化,再进 Attention
hidden_states, present_key_value = self.self_attn(
self.input_layernorm(hidden_states),
position_embeddings,
past_key_value, use_cache, attention_mask
)
# 3. 将 Attention 的输出与原始输入相加
hidden_states += residual
# 4. 第二个残差连接
residual = hidden_states
# 5. Pre-Norm: 先归一化,再进 MLP (FFN 或 MoE)
mlp_output = self.mlp(self.post_attention_layernorm(hidden_states))
# 6. 将 MLP 的输出与 Attention 之后的输入相加
hidden_states = residual + mlp_output
return hidden_states, present_key_value
MiniMindBlock是Transformer的基本构建单元。它清晰地展示了现代Transformer的Pre-Norm结构。
- 第一个子层(注意力):
- 首先用
residual = hidden_states保存一份输入的“快照”。 - 然后对输入进行
input_layernorm归一化,再送入self_attn注意力模块。 - 最后,将注意力模块的输出与之前保存的
residual相加。这个“加”的操作就是残差连接,它像一条高速公路,让梯度可以更顺畅地在深层网络中传播,极大地稳定了训练。
- 首先用
- 第二个子层(前馈网络):
- 与第一子层完全相同的模式:保存残差、进行
post_attention_layernorm归一化、送入self.mlp(可能是FFN或MoE)、再与残差相加。
- 与第一子层完全相同的模式:保存残差、进行
整个MiniMindBlock就是这样一套“归一化 -> 计算 -> 残差连接”的流程的两次重复。
7. MiniMindModel#
class MiniMindModel(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
# 1. 词嵌入层:将 token ID 转换为向量
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size)
# 2. 创建多个 MiniMindBlock 层(config中的8层)
self.layers = nn.ModuleList([MiniMindBlock(l, config) for l in range(config.num_hidden_layers)])
# 3. 最后的归一化层
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# 4. 预计算 RoPE 的 cos 和 sin 值,并注册为 buffer
freqs_cos, freqs_sin = precompute_freqs_cis(...)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)
def forward(self, input_ids, ...):
# 5. 将输入 ID 转换为词嵌入向量
hidden_states = self.embed_tokens(input_ids)
# 6. 准备当前序列需要的 RoPE 位置编码
position_embeddings = (
self.freqs_cos[start_pos:start_pos + seq_length],
self.freqs_sin[start_pos:start_pos + seq_length]
)
# 7. 循环,让数据依次流过每一个 MiniMindBlock 层
for layer in self.layers:
hidden_states, present = layer(
hidden_states,
position_embeddings,
...
)
# 8. 对最后一层的输出进行最终的归一化
hidden_states = self.norm(hidden_states)
return hidden_states, ...
MiniMindModel是模型的骨干。
- 初始化: 它创建了词嵌入层
embed_tokens,一个包含num_hidden_layers个MiniMindBlock的列表self.layers,以及一个最终的norm层。最重要的是,它调用precompute_freqs_cis来生成RoPE查找表,并用register_buffer将其存入模型状态,这样它就可以随模型一起移动到GPU等设备。 - 前向传播:
- 首先通过
embed_tokens将输入的数字ID序列变成向量。 - 然后从预计算的buffer中,根据当前序列的长度和位置,切片出需要的
position_embeddings。 - 接下来是一个核心的
for循环,它让数据像流水线一样,依次通过self.layers中的每一个MiniMindBlock,每一层都会对hidden_states进行更深层次的加工。 - 最后,将所有层处理完毕的结果通过
self.norm进行最后一次归一化。
- 首先通过
8. MiniMindForCausalLM#
class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):
config_class = MiniMindConfig
def __init__(self, config: MiniMindConfig):
super().__init__(config)
# 1. 包含一个完整的 MiniMindModel 作为其骨干网络
self.model = MiniMindModel(config)
# 2. 创建一个线性层作为“语言模型头”,用于预测下一个词
# 它的输出维度是词汇表大小 vocab_size
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
# 3. 权重绑定:让输入嵌入层和输出预测头的权重共享
self.model.embed_tokens.weight = self.lm_head.weight
def forward(self, input_ids, ...):
# 4. 首先,调用骨干网络 self.model 进行所有核心计算
h, past_kvs, aux_loss = self.model(
input_ids=input_ids,
...
)
# 5. 将骨干网络的输出 h 通过 lm_head,得到最终的 logits
# logits 的维度是 (batch_size, seq_len, vocab_size)
logits = self.lm_head(h)
# 6. 将 logits 和其他信息 (如kv缓存) 封装并返回
return CausalLMOutputWithPast(logits=logits, past_key_values=past_kvs, ...)
这是最终可以直接使用的、面向因果语言建模任务的完整模型。
- 初始化: 它内部创建了一个
MiniMindModel实例。然后,它创建了整个模型最顶层的lm_head。这是一个简单的线性层,但至关重要,因为它负责将模型内部hidden_size维度的语义表示,映射回vocab_size维度的词汇表空间。 - 权重绑定 (Weight Tying):
self.model.embed_tokens.weight = self.lm_head.weight是一个非常重要的优化。它强制输入端的“词->向量”映射矩阵和输出端的“向量->词”映射矩阵使用同一组参数。这大大减少了模型的总参数量,并且通常能提升性能,因为它使得输入和输出的语义空间保持一致。 - 前向传播: 它的
forward非常直接:- 首先调用
self.model完成所有的Transformer计算,得到高级特征h。 - 然后将
h传递给self.lm_head,得到logits。logits向量中的每一个值,可以被理解为模型预测下一个词是词汇表中对应位置的那个词的“信心分数”。这个logits可以直接用来计算损失函数进行训练,或者通过Softmax转换成概率来进行文本生成。
- 首先调用